一文探讨可解释深度学习技术在医疗图像诊断中
作者:仵冀颖
编辑:Joni
本文依托于综述性文章,首先回顾了可解释性方法的主要分类以及可解释深度学习在医疗图像诊断领域中应用的主要方法。然后,结合三篇文章具体分析了可解释深度学习模型在医疗图像分析中的应用。
作为一种领先的人工智能方法,深度学习应用于各种医学诊断任务都是非常有效的,在某些方面甚至超过了人类专家。其中,一些计算机视觉方面的最新技术已经应用于医学成像任务中,如阿尔茨海默病的分类、肺癌检测、视网膜疾病检测等。但是,这些方法都没有在医学领域中得以广泛推广,除了计算成本高、训练样本数据缺乏等因素外,深度学习方法本身的黑盒特性是阻碍其应用的主要原因。
尽管深度学习方法有着比较完备的数学统计原理,但对于给定任务的知识表征学习尚缺乏明确解释。深度学习的黑盒特性以及检查黑盒模型行为工具的缺乏影响了其在众多领域中的应用,比如医学领域以及金融领域、自动驾驶领域等。在这些领域中,所使用模型的可解释性和可靠性是影响最终用户信任的关键因素。由于深度学习模型不可解释,研究人员无法将模型中的神经元权重直接理解 / 解释为知识。此外,一些文章的研究结果表明,无论是激活的幅度或选择性,还是对网络决策的影响,都不足以决定一个神经元对给定任务的重要性[2] ,即,现有的深度学习模型中的主要参数和结构都不能直接解释模型。因此,在医学、金融、自动驾驶等领域中深度学习方法尚未实现广泛的推广应用。
可解释性是指当人们在了解或解决一件事情的过程中,能够获得所需要的足够的可以理解的信息。深度学习方法的可解释性则是指能够理解深度学习模型内部机制以及能够理解深度学习模型的结果。关于 “可解释性” 英文有两个对应的单词,分别是 “Explainability” 和“Interpretability”。这两个单词在文献中经常是互换使用的。一般来说,“Interpretability”主要是指将一个抽象概念(如输出类别)映射到一个域示例(Domain Example),而 “Explainability” 则是指能够生成一组域特征(Domain Features),例如图像的像素,这些特征有助于模型的输出决策。本文聚焦的是医学影像学背景下深度学习模型的可解释性(Explainability)研究。
可解释性在医学领域中是非常重要的。一个医疗诊断系统必须是透明的(transparent)、可理解的(understandable)、可解释的(explainable),以获得医生、监管者和病人的信任。理想情况下,它应该能够向所有相关方解释做出某个决定的完整逻辑。公平、可信地使用人工智能,是在现实世界中部署人工智能方法或模型的关键因素。本文重点关注可解释深度学习方法在医疗图像诊断中的应用。由于医学图像自有的特点,构建用于医疗图像分析的可解释深度学习模型与其它领域中的应用是不同的。本文依托于综述性文章[1],首先回顾了可解释性方法的主要分类以及可解释深度学习在医疗图像诊断领域中应用的主要方法。然后,结合三篇文章具体分析了可解释深度学习模型在医疗图像分析中的应用。
一、可解释深度学习模型在医疗图像分析中的应用综述[1]
1.1 可解释性方法分类
首先,我们来了解一下可解释性方法的分类。针对可解释性方法的分类问题研究人员提出了多种分类方式,但是这些方式都不是绝对的,即这些方法都是非排他性的,不同的分类方法之间存在重叠。图 1 给出可解释性分类方法的示例(可解释性人工智能工具(Explainable AI ,XAI)):
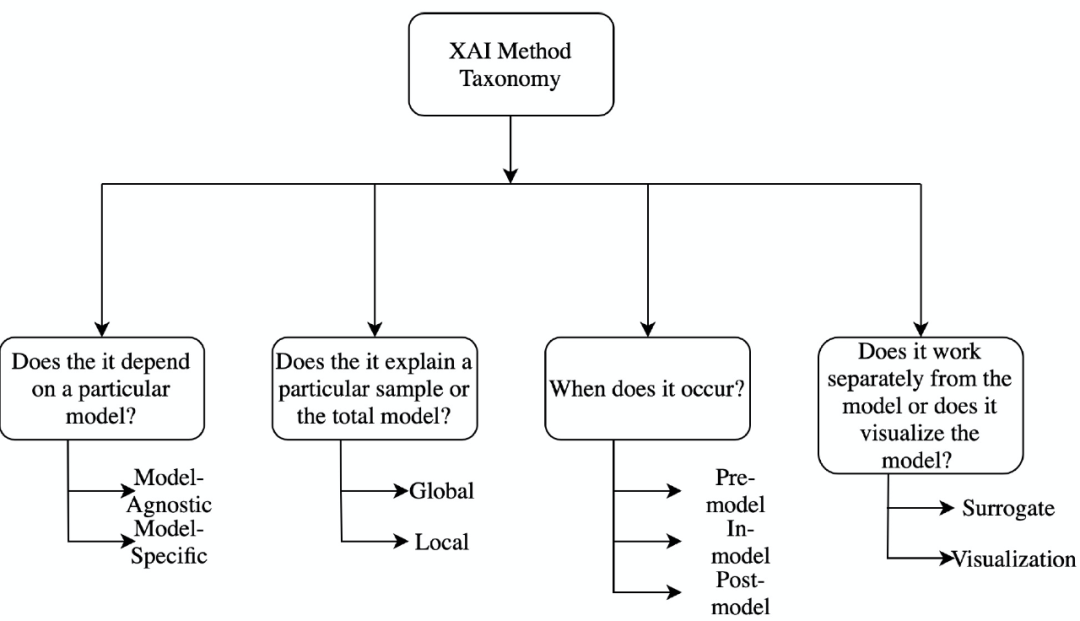
图1. XAI 主要分类方法示例
1.1.1 模型特定的方法 vs 模型无关方法(Model Specific vs Model Agnostic)
模型特定的方法基于单个模型的参数进行解释。例如,基于图神经网络的可解释方法(Graph neural network explainer,GNNExplainer)主要针对 GNN 的参数进行解释。模型无关方法并不局限于特定的模型体系结构。这些方法不能直接访问内部模型权重或结构参数,主要适用于事后分析。
1.1.2 全局方法 vs 局部方法(Global Methods vs Local Methods)
局部可解释性方法主要聚焦于模型的单个输出结果,一般通过设计能够解释特定预测或输出结果的原因的方法来实现。相反,全局方法通过利用关于模型、训练和相关数据的整体知识聚焦于模型本身,它试图从总体上解释模型的行为。特征重要性是全局方法的一个很好的例子,它试图找出在所有不同的特征中对模型性能有更好影响的特征。
1.1.3 模型前 vs 模型中 vs 模型后方法(Pre-model vs in-model vs post-model)
模型前方法是一类独立的、不依赖于任何深度学习模型结构的可解释性方法,主成分分析(PCA)、流形学习中的 t-SNE 都属于这一类方法。集成在深度学习模型本身中的可解释性方法称为模型中方法。模型后方法则是在建立深度学习模型之后实施的,这一类方法主要聚焦于找出模型在训练过程中究竟学到了什么。
1.1.4 替代方法 vs 可视化方法(Surrogate Methods vs Visualization Methods)
替代方法由不同的模型组成一个整体,用于分析其他黑盒模型。通过比较黑盒模型和替代模型来解释替代模型的决策,从而辅助理解黑盒模型。决策树(Decision tree)就是替代方法的一个例子。可视化方法并不是构建一个新的不同的模型,而是通过可视化的方法,例如激活图(Activation Maps),帮助解释模型的某些部分。
1.2 可解释深度学习模型在医疗图像分析中的应用分类
具体到医疗图像分析领域,引入可解释性方法的可解释深度学习模型主要有两类:属性方法(attribution based)和非属性方法(non-attribution based)。两类方法的主要区别在于是否已经确定了输入特征对目标神经元的联系。属性方法的目标是直接确认输入特征对于深度学习网络中目标神经元的贡献程度。而非属性方法则是针对给定的专门问题开发并验证一种可解释性方法,例如生成专门的注意力、知识或解释性去辅助实现专门问题的可解释深度学习。
1.2.1 属性方法
属性方法的目标是确定输入特征对目标神经元的贡献,通常将分类问题正确类别的输出神经元确定为目标神经元。所有输入特征的属性在输入样本形状中的排列形成热图(heatmaps),称为属性映射(Attribution Maps)。图 2 给出了不同图像的属性映射示例[3]。对目标神经元激活有积极贡献的特征用红色标记,而对激活有负面影响的特征则用蓝色标记。
上一篇:2021年8月27日Science期刊精华
下一篇:福州大学圆二色光谱仪采购项目招标公告