历时22年,超2亿个缺失的人类基因组首次破译|
历时22年,超2亿个缺失的人类基因组首次破译|钛媒体科普

研究完整人类基因组的DNA碱基,以字母A、T、C和G为代表(来源:NHGRI)
历时22年,研究人员终于从头到尾破译了完整的人类基因组序列。
钛媒体App 4月1日消息,据科技日报,全球顶级期刊《Science》(科学)杂志今天凌晨连发6篇论文报告,公布了人类基因组测序的最新进展:国家人类基因组研究中心(NHGRI)组成的端粒到端粒 (T2T) 联盟科学团队,通过新的技术研究出全球第一个完整的、无间隙的人类基因组序列,首次揭示了高度相同的节段重复基因组区域及其在人类基因组中的变异。
这是对标准人类参考基因组,即2013年发布的参考基因组序列(GRCh38)的“重大升级”,增加了之前整条染色体上隐藏的DNA片段,破译了缺失的大约2亿个DNA碱基对以及2000多个新基因——占人类基因组的8%。
这篇研究成果意义重大。科研人员揭示的完整人类基因组序列,是世界上最复杂的谜题之一,这一研究使得人类第一次看到最完整的、无间隙的DNA碱基基因序列,对于人类了解基因组变异的全谱,以及某些疾病的遗传贡献至关重要,将会推动与癌症、出生缺陷和衰老相关的研究与科学发展。
同时,这也是《Science》创刊141年来,首次在同一期杂志中连发6篇论文揭示人类基因组研究。
本论文作者,圣路易斯华盛顿大学医学院遗传学家Ting Wang(音译:王庭)表示,此次拥有完整的基因组,一定会改善生物医学研究。“毫无疑问,这是一项重要的成就。”
据中国科学报,人类基因组计划参与者、中国科学院北京基因组研究所研究员于军表示,假如把人类基因组序列比作一辆非常复杂的汽车,那么与20年前完成的人类基因组草图相比,完整的新序列相当于增添了更多零件。
“我们看到了以前从未阅读过的章节,”本论文通讯作者,华盛顿大学霍华德-休斯医学研究所(HHMI)研究员Evan Eichler(艾希勒)表示,这是全行业的一件大事。

Science封面图
研究人员到底破译了什么?
人类基因组由超过60亿个独立的DNA碱基、大约2-3万个蛋白质编码基因(整个基因仍未有统一答案)组成,与黑猩猩等其他灵长类动物的数量差不多,分布在23对染色体上。为了读取数以万计的基因组,科学家们首先将所有的DNA链切成几百到几千个单位长度的DNA片段。然后用测序机器读取每个片段中的各个碱基,科学家们试图按照正确的顺序组装这些片段,就像拼凑一个复杂的拼图。
2001年2月12日,由6国科学家共同参与的国际人类基因组计划首次公布人类基因组图谱及初步分析结果;2003年4月15日,公布了人类基因组序列草图。
然而,由于技术限制,当初的人类基因组计划留下了大约8%的“空白”间隙。这部分很难被测序,由高度重复、复杂的DNA块组成,其中包含功能基因以及位于染色体中间和末端的着丝粒和端粒。
实际上,核心的挑战在于,基因组的某些区域反复重复相同的碱基。重复的区域包括着丝粒和核糖体DNA等,过去无法按照正确的顺序组装一些被切碎的片段。这就像拥有相同的拼图碎片一样,科学家们不知道哪块碎片在哪里,因此基因组图中留下了很大的空白。
而且大多数细胞包含两个基因组--一个来自父亲,一个来自母亲。当研究人员试图组装所有的片段时,来自父母双方的序列可能混合在一起,掩盖了个体基因组内的实际变异。
如今,研究人员通过新的纳米机器设备与核心技术,实现了新的无间隙版本T2T-CHM13,由30.55亿个碱基对和19969个蛋白质编码基因组成。增加了近2亿个碱基对的新DNA序列,包括99个可能编码蛋白质的基因和其中近2000个需要进一步研究的候选基因。
这些候选基因大多数是失活的,但其中115个仍然可能表达。团队还在人类基因组中发现了大约200万个额外的变异,其中622个出现在与医学相关的基因中。此外,新序列还纠正了GRCh38中的数千个结构错误。
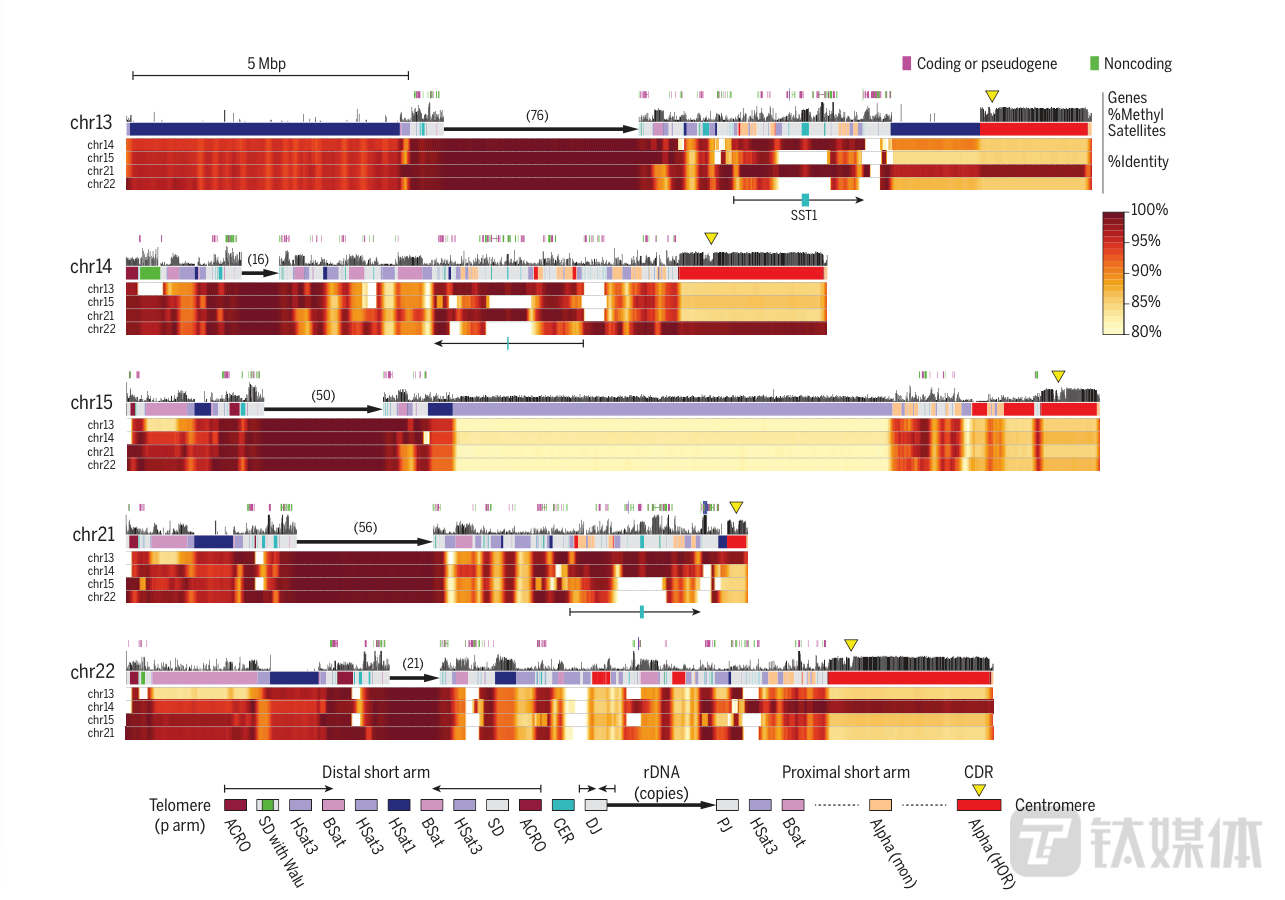
近端着丝粒染色体的显示图样(来源:论文)
上一篇:表达基因的首份综合功能图谱发布,将人类基因与其功能一一对应
下一篇:华大基因控股股东华大控股质押630万股 用于自身